320x100
320x100
unstack()
group by 를 사용하고 unstack() 을 이용하여 컬럼을 가져올 수 있다.
group by 하는 컬럼 중
예를 들어, ["A","B"]라고 한다면,
끝에있는 index B를 컬럼으로 가지고 온다.
실제 데이터로 확인해보자

지역별 평당 분양가격 데이터이다.
여기서 지역명, 전용면적으로 평당분양가격의 평균을 구하고자 하면, 아래 코딩과 같다.
df_last.groupby(["지역명","전용면적"])["평당분양가격"].mean()
하지만, 컬럼으로 된 데이터로 확인하고 싶을 때, unstack() 을 사용한다.
df_last.groupby(["지역명","전용면적"])["평당분양가격"].mean().unstack()
더 깔끔하다.
아까 처음에 ["A","B"]라고 한다면, 끝에있는 index B를 컬럼으로 가지고 온다고 했는데
데이터를 확인해보면 전용면적을 컬럼으로 가져오는것을 확인할 수 있다.
transpose
행과 열을 변경하고 싶다면 transpose()를 사용한다.
예를 들어 연도, 지역명으로 평당분양가격의 평균을 구합니다.
unstack()을 사용한다면, 컬럼이 마지막 인덱스인 B, 즉 지역명이 올것이다.
여기서 transpose() 를 사용한다면, 연도가 컬럼으로 온다.
g = df_last.groupby(["연도","지역명"])["평당분양가격"].mean().unstack()
g.transpose()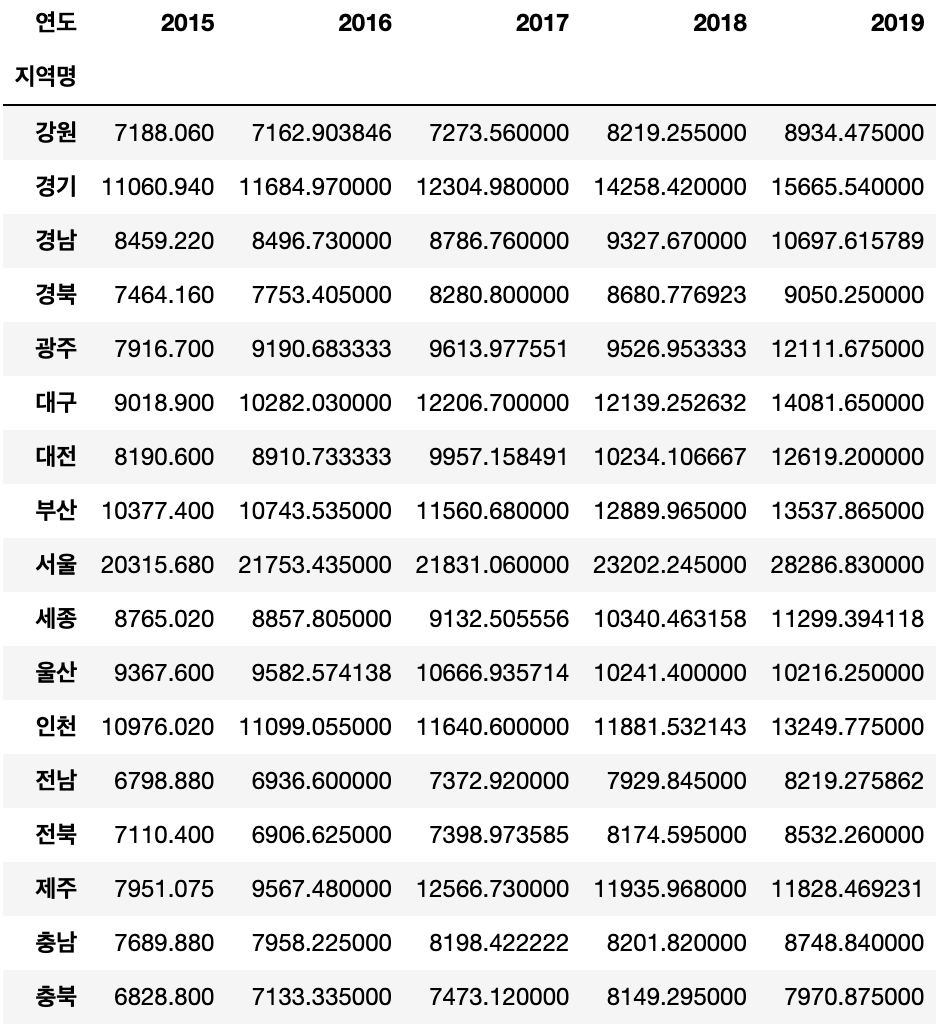
320x100
320x100
'빅데이터 관련 자료 > Python' 카테고리의 다른 글
| 파이썬에서 데이터 읽는 방법 (0) | 2024.03.06 |
|---|---|
| Python 파이썬, 왜 다들 파이썬 파이썬 그러는가? (0) | 2023.10.31 |
| ValueError: invalid literal for int() with base 10: ' ' 주피터 파이썬 에러 (0) | 2023.01.30 |
| Jupyter 주피터 파이썬 에러 Unicode Decode Error (0) | 2023.01.29 |
| WARNING: Python 2.7 is not recommended 해결, 맥에 파이썬 설치하기 (0) | 2022.02.26 |