UNIT 5-1 분류 및 군집화 문제
분류 vs 군집화
분류
- 지도학습
- 각 데이터 개체별로 class/label이 뭔지, 어떤 그룹에 속하는지 예측하는 문제
- 학습 데이터에 label정보가 필요함
군집화
- 비지도학습
- 데이터 유사도를 기반으로 군집을 형성하는 문제
- 학습 데이터에 특별한 amotation이 필요하지 않음

UNIT 5-2 Logistic Regression(Revision)
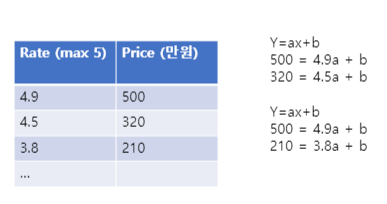



LSE: 최소제곱법, error의 제곱의 합을 구해 그 합이 최소가 되도록 하는 것
MLE: 최대우도법, 원하는 결과가 나올 가능성을 최대로 만들도록 하는 것
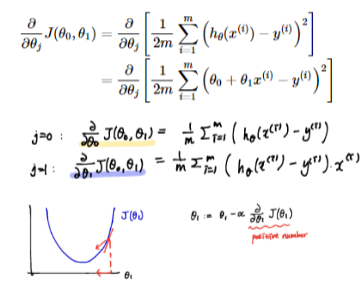
Multiclass Logistic Regression
Logistic Regression은 BInary Classification을 하기 위해 사용되는 것이 일반적
하지만, 이를 이용해서도 Mulitclass Classification을 할 수 있다.
Email -> spam, normal, important
One-vs-all(= One-vs-rest) 방식을 이용!
Email -> spam or not
Email -> normalor not
Email -> importantor not
Regularization
overfitting이 생기는 이유는 다양하지만, 너무 모델이 복잡해지면 생길 수 있다. 학습셋에 지나치게 너무 복잡하게 맞춰져서 일반화 성능을 가지지 못하는 경우가 발생하며, 이러한 점에서 해결책이 될 수 있는 방법 중 하나

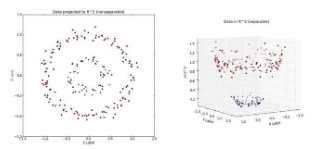
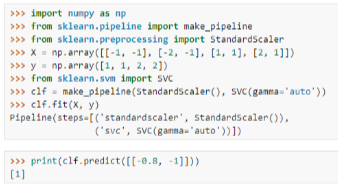
UNIT 5-3 Sipport Vectot Machine
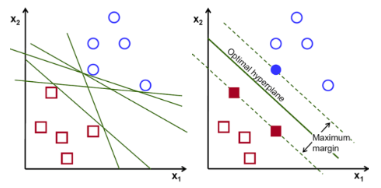
Support Vector를 통해서 Decision Boundary를 정의하는 모델
Support Vector decision boundary에 가장 가까운 데이터
최적의 decision boundary는 margin이 최대가 될 때
Support Vector를 잘 골라내면, 나머지 데이터는 무시할 수 있음 => 빠른 속도
UNIT 5-4 K-means Clustering
k-means clustering
- k개의 Equal variance의 그룹들로 데이터를 나누는것
- 각각의 그룹은 클러스터에 있는 샘플의 평균으로 설명됨
- k-means 알고리즘의 목표: inertia를 최소화하는 중심 또는 클러스터 내 제곱합 criterion을 최소화하는 것
- 핵심과정
1. 중심의 초기값 설정(렌덤 샘플)
2. 각 샘플을 가장 가까운 중심에 할당
3. 각 이전 중심에 할당된 모든 샘플의 평균값을 취하여 새로운 중심을 생성


q

UNIT 5-5 MeanShift
- smooth density를 가진 데이터 샘플에서 클러스터를 발견하는 것
- Centroid 기반 알고리즘
- Centroid의 후보를 주어진 영역 내 점들의 평균으로 업데이트하는 방식
- 가까운 Centroid 는 중복된 Cluster일 수 있으므로 제거
- 검색할 영역의 크기를 결정하는 매개변수 bandwidth 존재
- K-means와 다르게 자동으로 클러스터 수를 설정할 필요가 없음


github를 통해 확인
https://github.com/carpe1997/TIL/tree/main/Machine%20Learning/5%ED%9A%8C%EC%B0%A8
'빅데이터 관련 자료 > Machine Learning' 카테고리의 다른 글
| 머신러닝 데이터 분석 7회차 (0) | 2021.10.06 |
|---|---|
| 머신러닝 데이터 분석 6회차 (0) | 2021.09.29 |
| 머신러닝 데이터 분석 4회차 (0) | 2021.09.17 |
| 머신러닝 데이터 분석 3회차 (0) | 2021.09.13 |
| 머신러닝 데이터 분석 2회차 (0) | 2021.09.08 |