필요한 라이브러리 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
필요한 데이터셋 불러오기
df=sns.load_dataset("mpg")
df.shape
# (398,9)
데이터셋 일부만 가져오기
df.head()
데이터 요약하기
df.info()
결측치 보기
df.isnull().sum()
기술 통계 보기
df.describe()
범주형일 경우 include를 사용해 볼 수 있다.
df.describe(include="object")

수치형 변수 보기
수치형 변수 mpg의 unique 값 보기
df.nunique()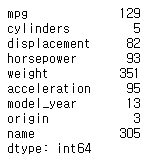
hist()를 통해 전체 수치변수에 대한 히스토그램을 그려본다.
figsize는 그래프의 크기이며, bins는 해당 막대의 영역(bin)를 얼마나 채우는지 결정해주는 변수이다.
df.hist(figsize=(10,10),bins=50)
비대칭도(왜도)
- 실수 값 확률 변수의 확률 분포 비대칭성을 나타내는 지표
- 왜도의 값은 양수나 음수가 될 수 있으며 정의되지 않을 수도 있음
- 왜도가 음수일 경우에는 확률밀도함수의 왼쪽 부분에 긴 꼬리를 가지며 자료가 오른쪽에 더 많이 분포
- 왜도가 양수일 때는 확률밀도함수의 오른쪽 부분에 긴 꼬리를 가지며 자료가 왼쪽에 더 많이 분포
- 평균과 중앙값이 같으면 왜도는 0

skew를 통해 전체 수치변수에 대한 왜도 구하기
df.skew()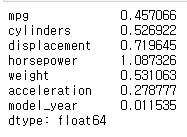
왜도값이 양수임으로 오른쪽으로 긴 꼬리 형태임을 알 수 있다.
첨도
- 확률분포의 뾰족한 정도를 나타내는 척도
- 관측치들이 어느 정도 집중적으로 중심에 몰려 있는가를 측정할 때 사용
- 첨도값(K)이 3에 가까우면 산포도가 정규분포에 가까움
- 3보다 작을 경우에는(K<3) 산포는 정규분포보다 더 뾰족한 분포(꼬리가 얇은 분포)
- 첨도값이 3보다 큰 양수이면(K>3) 정규분포보다 더 완만한 납작한 분포(꼬리가 두꺼운 분포)

kurt를 통해 전체 수치변수에 대한 첨도 구하기
df.kurt()
3을 기준으로 가까우면 정규분포에 가깝다. 첨도가 음수인게 대부분이라 대체적으로 완만한 종형태를 띤다.
seaborn 시각화
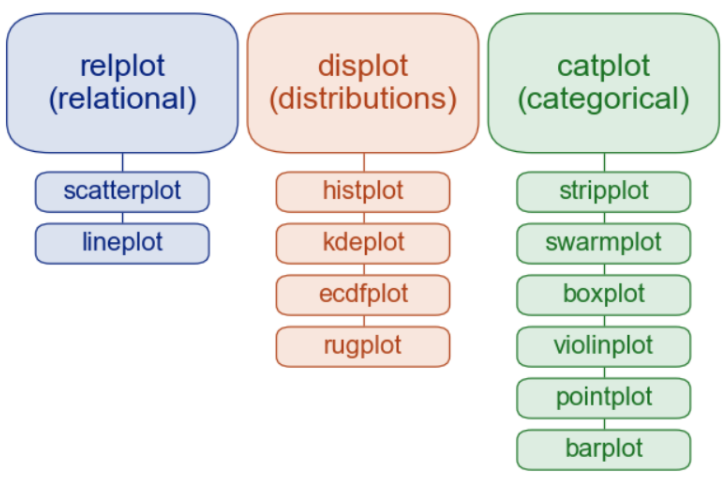
relplot: 수치형, displot: 수치형 분포, catplot: 범주형일떄 사용한다.
1개의 수치변수
displot을 통해 히스토그램과 kdeplot 그리기
sns.displot(data=df,x="mpg",kde=True,rug=True)
kdeplot, rugplot으로 밀도함수 표현하기
sns.kdeplot(data=df,x="mpg",shade=True,cut=3)
sns.rugplot(data=df,x="mpg")
boxplot 으로 mpg 의 사분위 수 표현하기
sns.boxplot(data=df,x="mpg")
violinplot 으로 mpg 값 보기
sns.violinplot(data=df,x="mpg")
2개 이상의 수치변수
scatterplot 을 통해 2개의 수치변수 비교하기
sns.scatterplot(data=df,x="weight",y="mpg") #음의 상관관계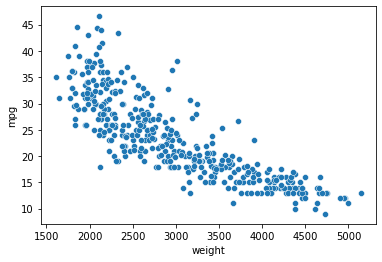
sns.scatterplot(data=df,x="weight",y="horsepower") #양의 상관관계

sns.scatterplot(data=df,x="weight",y="mpg",hue="origin")
regplot 으로 회귀선 그리기
sns.regplot(data=df,x="weight",y="mpg",ci=None)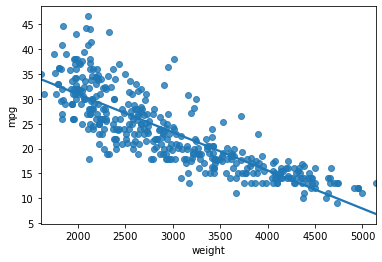
회귀선의 잔차를 시각화
sns.residplot(data=df,x="weight",y="mpg")
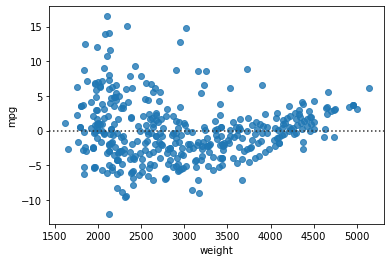
lmplot 을 통해 범주값에 따라 색상, 서브플롯 그리기
sns.lmplot(data=df,x="weight",y="mpg",hue="origin",col="origin",truncate=False,ci=None)
jointplot 2개의 수치변수 표현하기
sns.jointplot(data=df,x="weight",y="mpg",kind="hex")
lineplot으로 model_year, mpg를 시각화 합니다.
sns.lineplot(data=df,x="model_year",y="mpg",ci=None,hue="origin")
상관계수 구하기
corr()를 통해 데이터프레임 전체의 수치변수에 대해 상관계수를 구한다.
상관관계가 있다하더라도 인과관계가 있다는 것은 아니다.
corr=df.corr()
corr
mask= np.triu(np.ones_like(corr))
mask
heatmap 을 통해 상관계수를 시각화하면 다음과 같다.
sns.heatmap(corr,annot=True,cmap='RdBu',vmax=1,vmin=-1,mask=mask)
'빅데이터 관련 자료 > Python' 카테고리의 다른 글
| 파이썬 기초 - 8 (0) | 2021.11.12 |
|---|---|
| index_col, 원하는 컬럼을 인덱스로 지정하여 불러오기 (0) | 2021.10.25 |
| 파이썬 기초 - 5 (0) | 2021.07.29 |
| 파이썬 기초 - 4 (0) | 2021.07.26 |
| 파이썬 기초-3 (0) | 2021.07.22 |