랜덤포레스트 개념, 선언 (RandomForestRegressor()) 랜덤 포레스트는 여러 개의 의사결정나무를 만들어서 이들의 평균으로 예측의 성능을 높이는 방법이며, 이러한 기법을 앙상블 기법이라고 한다. 주어진 하나의 데이터로부터 여러 개의 랜덤 데이터셋을 추출해서, 각 데이터셋을 통해 모델을 여러개 만들 수 있따. from sklearn.ensemble import RandomForestRegressor model=RandomForestRegressor() 빅데이터 관련 자료/Dacon 2021.08.05
결측치 대체 보간법 결측치들을 평균값으로 대체하였으면, 이번에는 피쳐의 정보성을 강조하기 위해 보간보를 사용해서 결측치를 채우는 방법도 있다. 데이터에 따라서 결측치를 어떻게 대체할지 결정하는 것은 엔지니어의 결정이다. Python pandas의 interpolate() method를 사용해 구현하면 다음과 같다. df.interpolate(inplace=True) 빅데이터 관련 자료/Dacon 2021.08.04
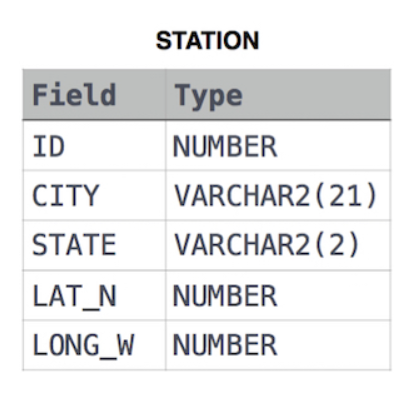
Weather Observation Station 6 Query the list of CITY names starting with vowels (i.e., a, e, i, o, or u) from STATION. Your result cannot contain duplicates. Input Format The STATION table is described as follows: # 나의 해답 SELECT CITY FROM STATION WHERE (SUBSTR(CITY,1,1) = 'A' or SUBSTR(CITY,1,1) = 'E' or SUBSTR(CITY,1,1) = 'I' or SUBSTR(CITY,1,1) = 'O' or SUBSTR(CITY,1,1) = 'U' ); 빅데이터 관련 자료/[SQL] Basic 2021.08.04
Weather Observation Station 5 Query the two cities in STATION with the shortest and longest CITY names, as well as their respective lengths (i.e.: number of characters in the name). If there is more than one smallest or largest city, choose the one that comes first when ordered alphabetically. The STATION table is described as follows: # 나의 해답 select * from (select city c, length(city) l from station order by l desc, c asc) .. 빅데이터 관련 자료/[SQL] Basic 2021.08.03
Lv2 | 전처리 | 결측치 평균으로 대체 (fillna({mean})) lv1에서 결측치들을 0으로 대체하였다. 하지만, 보다 나은 모델 성능을 위해서 결측치를 대체하는 방법은 여러가지 있다. 이번에는 각 피쳐의 평균값으로 대체해보겠다. 원하는 피쳐의 결측치를 해당 피쳐의 평균값으로 대체한다. df.fillna({'칼럼명':int(df['칼럼명'].mean)},implace=True) 결측치를 갖는 피쳐들을 탐색하고, 해당 피쳐들을 대체하고 나서, 결측치가 남아있는지 확인본다. df.isnull().sum() 빅데이터 관련 자료/Dacon 2021.08.03
Lv1 | 모델링 | 제출파일생성(to_csv()) 훈련시킨 모델로 테스트 파일을 예측하면 예측결과를 제출할 csv 파일을 만들어본다. 1. 백지의 답안지인 submission.csv 파일을 df 파일로 불러와서 예측결과를 덧입히기 2. 덧입혀준 df 파일을 csv 파일로 내보내기 3. 드라이브에 저장된 csv 파일을 다운받아 제출 빅데이터 관련 자료/Dacon 2021.08.02
Weather Observation Station 4 Find the difference between the total number of CITY entries in the table and the number of distinct CITY entries in the table. The STATION table is described as follows: # 나의 해답 SELECT COUNT(*)-COUNT(DISTINCT(CITY)) FROM STATION 빅데이터 관련 자료/[SQL] Basic 2021.08.02
파이썬 기초 - 6 필요한 라이브러리 불러오기 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns 필요한 데이터셋 불러오기 df=sns.load_dataset("mpg") df.shape # (398,9) 데이터셋 일부만 가져오기 df.head() 데이터 요약하기 df.info() 결측치 보기 df.isnull().sum() 기술 통계 보기 df.describe() 범주형일 경우 include를 사용해 볼 수 있다. df.describe(include="object") 수치형 변수 보기 수치형 변수 mpg의 unique 값 보기 df.nunique() hist()를 통해 전체 수치변수에 대한 히스토그램을 그려본.. 빅데이터 관련 자료/Python 2021.08.02
Weather Observation Station 3 Query a list of CITY names from STATION for cities that have an even ID number. Print the results in any order, but exclude duplicates from the answer. The STATION table is described as follows: # 나의 해답 SELECT DISTINCT(CITY) FROM STATION WHERE MOD(ID,2)=0; 빅데이터 관련 자료/[SQL] Basic 2021.08.01
테스트예측(predict()) 테스트 파일을 훈련된 모델로 예측해본다. 훈련된 모델에서 predict() 매서드에 예측하고자 하는 data를 인자로 넣어주게 되면 해당 결과 array를 할당할 수 있다. [할당할 array]= model.predict(test) 빅데이터 관련 자료/Dacon 2021.08.01
Weather Observation Station 1 Query a list of CITY and STATE from the STATION table. The STATION table is described as follows: # 나의 해답 SELECT CITY, STATE FROM STATION; 빅데이터 관련 자료/[SQL] Basic 2021.07.31
Lv1 | 모델링 | 모델훈련 (fit()) 모델을 선언한 후, fit(X,Y) 함수를 사용해서 모델을 훈련시킨다. 여기서 주의해야 할 점은 x 데이터는 예측에 사용되는 변수들이고 Y 데이터는 예측결과 변수여야 한다. x데이터는 train Data에서 drop(['제외할 컬럼명'],axis=1)을 함수를 이용해 예측할 피쳐를 제외할 수 있다. Y데이터는 train['예측할 컬럼명']으로 인덱싱할 수 있습니다. X_train = train.drop(['제외할컬럼명'], axis=1) Y_train = train['예측할컬럼명'] 이제 모델을 선언하고, fit() 함수를 이용해 모델을 훈련시킨다. model=DecisionRegressor() model.fit(X_train,Y_train) 빅데이터 관련 자료/Dacon 2021.07.31
Japanese Cities' Names Query the names of all the Japanese cities in the CITY table. The COUNTRYCODE for Japan is JPN. The CITY table is described as follows: # 나의 해답 SELECT NAME FROM CITY WHERE COUNTRYCODE ='JPN'; 빅데이터 관련 자료/[SQL] Basic 2021.07.30
Lv1 | 모델링 | 모델선언 (DecisionTreeClassifier()) 해당 라이브러리로부터 원하는 모듈을 불러오기 sklearn.Tree 에서 DecisionTreeRegressor 모듈을 불러온다. from sklearn.Tree import DecisionTreeRegressor model=DecisionTreeRegressor() 빅데이터 관련 자료/Dacon 2021.07.30
파이썬 기초 - 5 시각화 도구: seaborn 필요한 라이브러리 불러오기 import pandas as pd import seaborn as sns import numpy as np 필요한 데이터셋 불러오기 df=sns.load_dataset("anscombe") #씨본에서 제공하는 데이터, pd.read_csv("https://raw.githubusercontent.com/mwaskom/seaborn-data/master/anscombe.csv") 똑같음 df.shape #(44, 3) df_1,2,3,4, 만들기 df_1=df[df["dataset"]=='I'] df_1.describe() df_1.corr() df_2,3,4도 똑같이 생성하면 된다. series 빈도수 구하기 - value_counts() df["d.. 빅데이터 관련 자료/Python 2021.07.29
EDA Project - 데이터 시각화(태블로 결과물) EDA Project 프로젝트 기간: 7월 14일 ~ 8월 2일 팀명: 플로우 멘토: 윤00(머신러닝 엔지니어) 팀원: 최00, 박상욱, 홍00, 김00 담당매니저: 김00 개최: NanoDegree 광고 타켓 지표 대시보드 태블로로 시각화 - 연도-월마다 요일별 시간대 주문 시각화 - State 별 주문 건수(Top5 state-) 시각화 - 카테고리별 주문 건수 시각화 - 주문 트렌드 시각화 https://public.tableau.com/app/profile/in.wha.hong/viz/1_16270920202890/1 1차 프로젝트 1차 프로젝트 public.tableau.com Notion 포트폴리오 https://www.notion.so/Brazil-E-commerce-Olist-busines.. 빅데이터 관련 자료/[Project ]Brazil E-commerce 2021.07.29
Japanese Cities' Attributes Query all attributes of every Japanese city in the CITY table. The COUNTRYCODE for Japan is JPN. The CITY table is described as follows: # 나의 해답 SELECT * FROM CITY WHERE COUNTRYCODE ='JPN'; 카테고리 없음 2021.07.29
Lv1 | 모델링 | 모델개념 (의사결정나무) # 의사결정나무란? 결정 트리는 의사 결정 규칙과 그 결과들을 트리 구조로 도식화한 의사 결정 지원 도구의 일종이다. A 를 만족하는가? True False B를 만족하는가? C를 만족하는가? True False True False D 이다 F이다 G이다 H이다 EDA를 통해 data를 살펴보면 각 행들은 피쳐들을 갖고 있다. 이 중 하나의 피쳐를 정해서 해당 피쳐의 값에 대해 특정한 하나의 값을 정한다면, 이를 기준으로 모든 행들을 두개의 노드로 분류할 수 있다. 대표적인 의사결정나무인 CART 의사결정 나무는 이진분할을 사용한다. 파생된 두 개의 노드에 대해서 또 다시 새로운 피쳐의 특정한 값을 정하고 분류를 정한다. 이 과정을 반복하게 되면 점점 피쳐의 값에 따라 data들이 분류가 되는데 이를 의.. 카테고리 없음 2021.07.29
Select By ID Query all columns for a city in CITY with the ID 1661. The CITY table is described as follows: # 나의 해답 SELECT * FROM CITY WHERE ID=1661; 빅데이터 관련 자료/[SQL] Basic 2021.07.28
Lv1 | 모델링 | scikit-learn (DecisionTreeClassifier) import sklearn from sklearn.tree import DecisionTreeClassifier EDA를 통해 데이터를 살펴보고, 전처리를 하였다면, 본격적으로 머신러닝 모델을 훈련시키고, 훈련된 모델을 통해 예측을 한다. 선행 연구된 놀랍고 다양한 모델들이 있는데, 이러한 머신러닝 모델들을 TensorFlow, PyTorch 등 Python 오픈 소스 머신 러닝 라이브러를 통해 손쉽게 구현 가능하다 먼저 sckit-learn 라이브러리를 사용해 모델링을 시작한다. scikit-learn 홈페이지: https://scikit-learn.org/stable/ 빅데이터 관련 자료/Dacon 2021.07.28
Select All Query all columns (attributes) for every row in the CITY table. The CITY table is described as follows: # 나의 해답 SELECT * FROM CITY; 빅데이터 관련 자료/[SQL] Basic 2021.07.27
Lv1 | 전처리 | 결측치 삭제하기, 대체하기 (dropna(), fillna()) dropna()를 사용하면, 결측치를 갖는 행을 DataFrame 객체에서 삭제한다. 결측치를 처리하는 방법 중 가장 쉽고 간단한 방법인 결측치를 제거 하는 방법을 사용하겠다. DataFrame.dropna() fillna()를 사용해 모든 결측치를 인자값으로 대체할 수 있다. DataFrame.fillna() 빅데이터 관련 자료/Dacon 2021.07.27
EDA Project - 데이터 분석 EDA Project 프로젝트 기간: 7월 14일 ~ 8월 2일 팀명: 플로우 멘토: 윤00(머신러닝 엔지니어) 팀원: 최00, 박상욱, 홍00, 김00 담당매니저: 김00 개최: NanoDegree 4. 데이터 분석 전처리 된 데이터를 가지고 본격적으로 데이터 분석을 시작하였다. 내가 한 분석을 위주로 설명을 하겠다. 4.1 날짜, 시간, 요일별 소비 패턴 파악하기 분석 의도 광고는 많은 사람들에게 노출이 되어야 그 효과를 제대로 발휘 할 수 있다. 브라질의 국민들이 어떤 요일에, 어떤 시간대에 주로 주문을 하는지를 파악한다면, 언제 광고를 노출 시켜야 가장 효율적인 홍보 효과를 누릴 수 있는지를 파악하고자 하였다. 2016년부터 2018년까지 전체적인 브라질 상품 주문량의 증감 추이를 시계열로 분석하.. 빅데이터 관련 자료/[Project ]Brazil E-commerce 2021.07.27
파이썬 기초 - 4 import 필요한 라이브러리를 로드 import pandas as pd import numpy as np import seaborn as sns DataFrame 행과 열로 구성된 비어있는 데이터프레임을 생성 df = pd.DataFrame() df 컬럼 추가하기 df["자동차"]=["소형차", "중형차", "대형차", "소형차", "대형차", "중형차"] df["가격"]=[3000, 5000, 7000, 4000, 9000, 7000] df["가격"] #series형태 df[["가격"]] #dataframe 형태 tolist() 가격 컬럼전체를 리스트 형태로 변경합니다. df["가격"].tolist() 컬럼값 변경하기 df.columns=['차종류','시세'] 데이터 요약하기 df.info() # 해.. 빅데이터 관련 자료/Python 2021.07.26
Revising the Select Query II Query the NAME field for all American cities in the CITY table with populations larger than 120000. The CountryCode for America is USA. The CITY table is described as follows: # 나의 해답 SELECT NAME FROM CITY WHERE POPULATION>120000 AND CountryCode ='USA'; 빅데이터 관련 자료/[SQL] Basic 2021.07.26
Lv1 | 전처리 | 데이터 결측치 확인하기 (info()) DataFrame에 info() 매서드를 사용하면, 피쳐들의 결측치와 데이터 타입을 확인할 수 있다. 모델링에 앞서 결측치가있다면, 결측치들을 어떻게 다뤄야할지 고민하고 처리하는 과정이 필요하다. df.info() 빅데이터 관련 자료/Dacon 2021.07.26
Lv1 | EDA | 결측치 확인하기 (is_null()) 결측치는 말 그대로 데이터에 값이 없는 것을 뜻한다. 줄여서 'NA' 또는 'NULL' 이라고 표현한다. pandas에서는 결측치를 NaN으로 표현하며, isnull() 메서드를 사용하면 DataFrame에서 NaN 값을 확인할 수 있다. isnull() 메서드는 DataFrame에서 데이터가 NaN 값이면 True로 , 그렇지 않으면 False로 리턴한다. import pandas as pd import numpy as np df=pd.DataFrame({'name':['a','b','c'],'age':[30,np.nan,19],'class':[np.nan,2,3]}) df.isnull() df.isnull().sum() 하게 되면 데이터 프레임의 각 열 별 결측치 수를 확인할 수 있다. 빅데이터 관련 자료/Dacon 2021.07.25
EDA Project - 데이터 전처리 EDA Project 프로젝트 기간: 7월 14일 ~ 8월 2일 팀명: 플로우 멘토: 윤00(머신러닝 엔지니어) 팀원: 최00, 박상욱, 홍00, 김00 담당매니저: 김00 개최: NanoDegree 3. 데이터 전처리 - 상품 카테고리명 한국어 번역 from googletrans import Translator # english to korea trans = Translator() result = trans.translate("english.", src='en', dest='ko') result.text category_list = order_df['product_category_name_english'].value_counts().index.tolist() print(category_list) cat.. 빅데이터 관련 자료/[Project ]Brazil E-commerce 2021.07.24
Lv1 | EDA | 데이터 확인하기 (head()) Pandas 라이브러리를 이용하여 데이터를 확인하는 방법 그 중 가장 대표적인 메서드: head() head() 메서드는 데이터를 전부 보여주지 않고 상단 부분만 출력하여 보인다. tail() 메서드는 하단 부분만 출력하여 보인다. import pandas as pd train=pd.read_csv("data/train.csv") train.head() train.tail() 빅데이터 관련 자료/Dacon 2021.07.24
Lv1 | EDA | 행열갯수 관찰하기 (shape) read_csv를 통해 csv파일을 pandas 라이브러리에서 제공하는 dataframe 객체로 변환했다면, 불러온 데이터의 행과 열의 갯수를 관찰할 수 있다. [DataFrame 변수명].shape df.shape 빅데이터 관련 자료/Dacon 2021.07.23