320x100
이상치 보기
서울의 평당분양가격이 특히 높은 데이터가 있습니다. 해당 데이터를 가져옵니다.
df_last[df_last["평당분양가격"]>40000]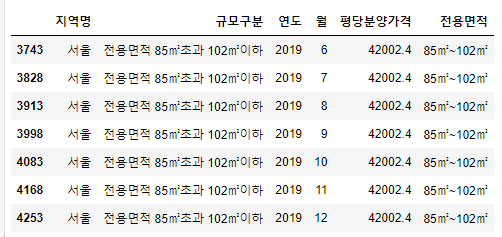
수치 데이터 히스토그램 그리기
df_last.hist(figsize=(10,6))
pairplot 그리기
sns.pairplot(data=df_last,hue="지역명") #hue를 안넣으면 히스토그램으로 작성됨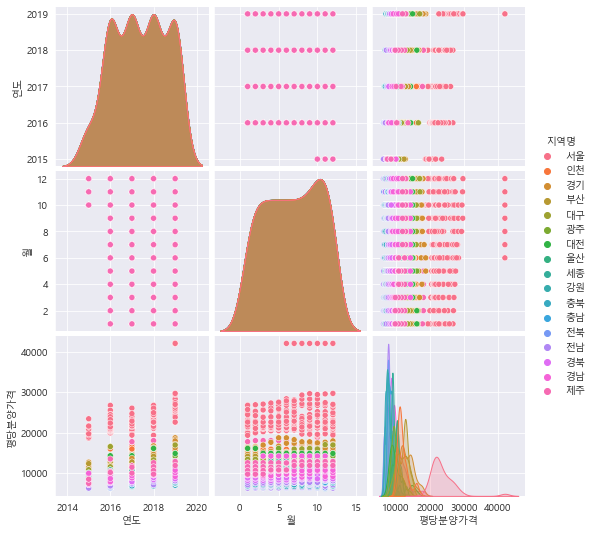
melt로 Tidy data 만들기
pandas의 melt를 사용하면 데이터의 형태를 변경할 수 있습니다. df_first 변수에 담긴 데이터프레임은 df_last에 담겨있는 데이터프레임의 모습과 다릅니다. 같은 형태로 만들어주어야 데이터를 합칠 수 있습니다. 데이터를 병합하기 위해 melt를 사용해 열에 있는 데이터를 행으로 녹여봅니다.
df_first_melt=pd.melt(df_first,id_vars="지역")
df_first_melt.head()df_first_melt 변수에 담겨진 컬럼의 이름을 ["지역명", "기간", "평당분양가격"] 으로 변경합니다.
df_first_melt.columns=["지역명","기간","평당분양가격"]
df_first_melt.head() #연도와 월 나눠야된다.연도와 월을 분리하기
parse_year라는 함수를 만듭니다. 연도만 반환하도록 하며, 반환하는 데이터는 int 타입이 되도록 합니다.
def parse_year(date):
year=date.split("년")[0]
year=int(year)
return yearparse_month 라는 함수를 만듭니다. 월만 반환하도록 하며, 반환하는 데이터는 int 타입이 되도록 합니다.
def parse_month(date):
month=date.split("년")[1].replace("월","")
month=int(month)
return monthdf_first_melt 변수에 담긴 데이터프레임에서 apply를 활용해 연도만 추출해서 새로운 컬럼에 담습니다.
df_first_melt["연도"]=df_first_melt["기간"].apply(parse_year)
df_first_melt
# map시리즈
# apply 시리즈 데이터 프레임 사용 가능df_first_melt 변수에 담긴 데이터프레임에서 apply를 활용해 월만 추출해서 새로운 컬럼에 담습니다.
df_first_melt["월"]=df_first_melt["기간"].apply(parse_month)
df_first_melt최근 데이터가 담긴 df_last 에는 전용면적이 있습니다. 이전 데이터에는 전용면적이 없기 때문에 "전체"만 사용하도록 합니다. loc를 사용해서 전체에 해당하는 면적만 copy로 복사해서 df_last_prepare 변수에 담습니다.
cols = ['지역명', '연도', '월', '평당분양가격']
df_last_prepare=df_last.loc[df_last["전용면적"]=="전체",cols]
df_last_preparedf_first_melt에서 공통된 컬럼만 가져온 뒤 copy로 복사해서 df_first_prepare 변수에 담습니다.
df_first_prepare=df_first_melt[cols]
df_first_prepare320x100
320x100
'빅데이터 관련 자료 > Python' 카테고리의 다른 글
| FinanceDataReader 파이썬 실습 - 2 (0) | 2022.02.18 |
|---|---|
| 전국 신규 민간 아파트 분양가격 동향 데이터 분석 - (4) (0) | 2022.01.18 |
| 전국 신규 민간 아파트 분양가격 동향 데이터 분석 - (2) (0) | 2022.01.15 |
| 전국 신규 민간 아파트 분양가격 동향 데이터 분석 - (1) (0) | 2022.01.14 |
| 파이썬 기초용어 정리 - 제어문, 입출력 etc (0) | 2022.01.05 |